https://arxiv.org/pdf/1409.1556.pdf
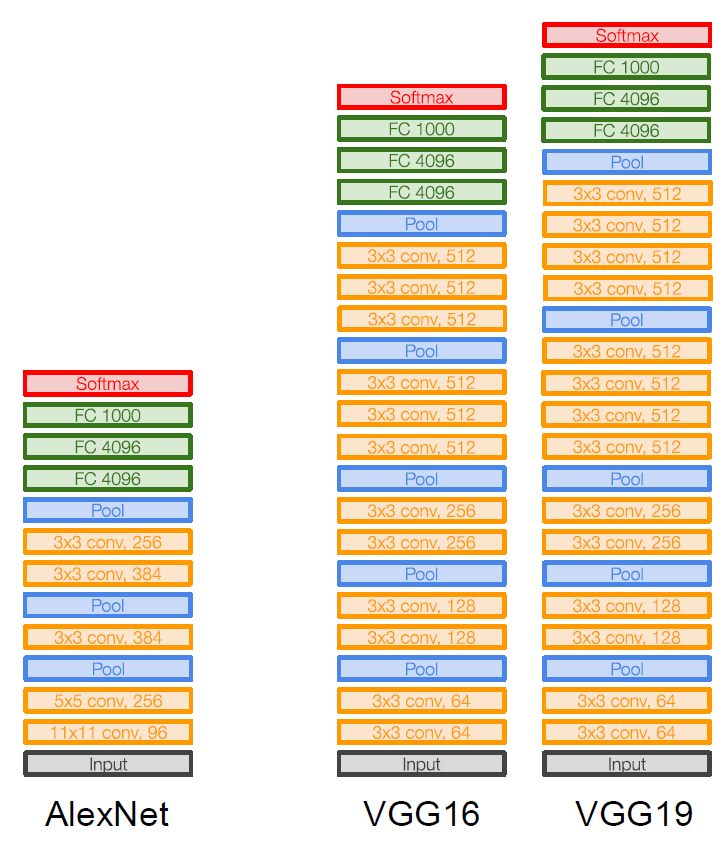
VGGNet
VGG-16
VGG논문은 convolutional network의 깊이를 증가시키면서 정확도 양상을 조사한다.
VGG모델은 3*3 convolution layer를 연속적으로 사용한 16-19 깊이의 모델이다.
Introduction
convnets이 컴퓨터 비전 분야에서 점점 상용화 되어가면서 더 좋은 정확도를 얻기 위해 AlexNet의 기본 구조를 향상시키기 위한 많은 시도가 이루어졌다. 이 논문에서는 Convnet 구조의 깊이에 집중한다. 이를 위해 더 많은 convolutional layer를 추가하였고 이것은 모든 layers에 매우 작은 3*3 convolution filters를 사용하였다.
ConvNet Configurations
ConvNet의 깊이가 증가함에 따른 성능 향상을 측정하기 위해 모든 conv layer의 파라미터를 동일하게 설정.
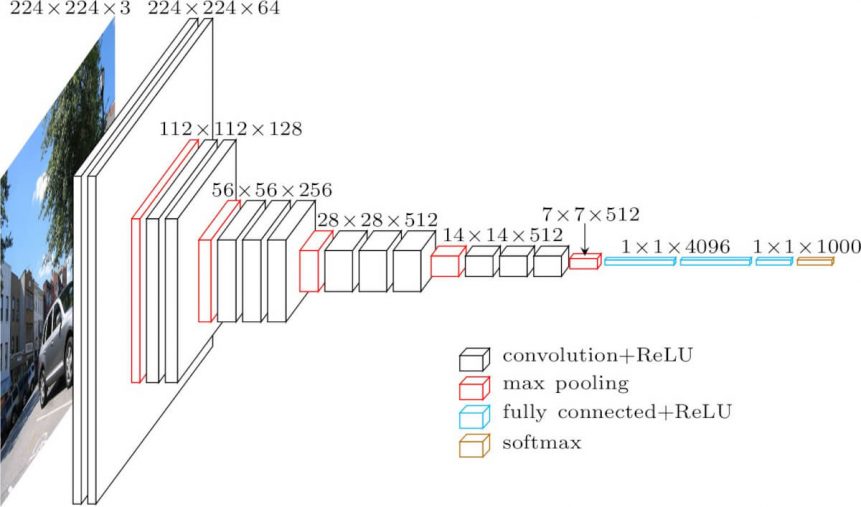
2.1 Architecture
ConvNet의 입력값은 고정된 크기의 224*224 RGB 이미지이다.
입력 이미지는 33 filter가 적용된 ConvNet에 전달되고, 또한 비선형성을 위해 11 convolutional filters도 적용한다.
(conv-conv-maxpooling = 하나의 VGG block. conv layer를 몇 번 반복할 것인지, filter 갯수를 몇 개를 쓸건지 결정해 비슷한 구조를 반복 )
일부 conv-layer에는 max-pooling(size = 2*2, stride = 2) layer를 적용한다.(maxpooling을 통해서 크기가 1/2로 줄어듦)
convolutional layers 다음에는 3개의 Fully - Connected layer가 있고, 첫 번째와 두 번째 FC에는 4096 channel, 세 번째 FC는 1000 channels를 갖고 있는 softmax layer이다. 모든 hidden layer에는 활성화 함수로 ReLU를 이용했다.
2.2 Configurations